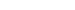




연구수행 내용 및 결과 |
 l 교육&연구 l 보유 장비 l 교육&연구 l 보유 장비 |
|
연구 주제 1 |
DC |
확장성 있는 다형 데이터 수집/정제/저장 플랫폼 구축 |
다형 데이터 수집을 위한 플랫폼 구축:
1차 년도에서 구축된 글로벌 웹 데이터 수집 시스템은 뉴스, 블로그, 게시판, SNS 등의 다양한 웹 도메인에서 제공되는 데이터를 다음 과정을 통해 수집 관리되고, 이를 정제, 색인화하고 이를 구조화하여 저장 시스템에 저장한다. 구축된 시스템의 주요 기능은 다음과 같다.

- 시나리오 기반 수집: 뉴스, 블로그, 쇼핑몰, 일반 홈페이지 등 다양한 사이트에서 사용자가 작성한 시나리오 기반으로 데이터를 추출하여 수집할 수 있도록 지원하는 수집 시스템이다.
- 웹 수집: URL 기반으로 사이트 전수 수집 또는 URL 패턴이나 키워드로 필터링 하여 사이트 내 정보를 수집할 수 있도록 지원하는 수집 시스템이다.
- RSS 수집: RSS의 피드를 읽어 들여 피드 내의 데이터와 링크 된 원본 데이터를 수집할 수 있도록 지원하는 수집 시스템이다.
- 메타 검색 수집: 구글, 빙, 다음, 네이버, 야후 등 다양한 검색 엔진의 검색 결과를 손쉽게 수집할 수 있도록 지원하는 수집 시스템이다.
- 소셜 데이터 수집: 트위터, 공개 페이스북 페이지, 웨이보 타임라인 등 다양한 형태의 소셜 데이터를 수집할 수 있도록 지원하는 수집 시스템이다.
웹 데이터 수집 시스템을 위하여 3대의 서버가 사용되고 있으며 글로벌 데이터 수집을 위한 확장을 고려하여 각 서버의 세부 사양은 다음과 같다.
Part Model Capacity Processor(s) Intel® Xeon® E5-2630v3 (2.4GHz, 8Core, 20MB, 85W, 8GT/s) 2EA: 2 CPU 16 Core Memory 16GB DDL4(1x16GB DIMMs, 2133 MHz) But, at 1866 MHz with the E5-2603v3 4EA: 64GB Network Controller HP Embedded 1Gb Ethernet 4-port 331i Adapter
Storage Controller HP Flexible Smart Array P440ar/2GB
Hard Drive HP 1TB 6G SAS 7.2K 2.5in SC MDL HDD 3EA: Physical 3TB, Logical 2TB(RAID5) PCI-Express Slots 2 Standard (1-FH/¾ L, 1-LP) PCIe 3.0
Power Supply (1) HP 500W Flex Slot Platinum Power Supply
Fans 5 Standard hot plug fans, redundant
Management iLO Management (standard), Intelligent Provisioning (standard)
3대의 서버는 다음과 같이 연동되어 동작한다.
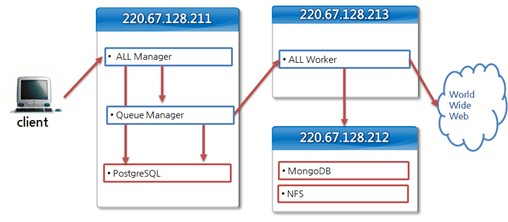
각 서버의 내부 구성 모듈은 다음 그림과 같다.
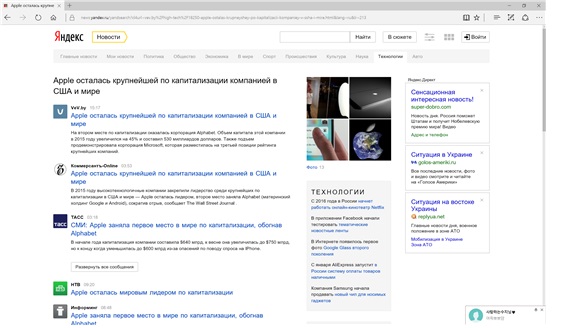
글로벌 웹 데이터를 수집하는 예로서 인도네시아어 사이트의 웹 수집 동작을 확인할 수 있다. 웹 수집은 URL을 입력으로 해당 사이트의 내용을 수집할 수 있으며 설정에 따라 특정 이미지를 선택할 수 있기 때문에 광고와 같은 불필요한 정보를 정제할 수 있다. 다음 그림은 클라이언트 프로그램을 이용한 웹 수집의 진행을 보여주고 있다.
토네이도에서 http://www.liputan6.com/index 크롤링
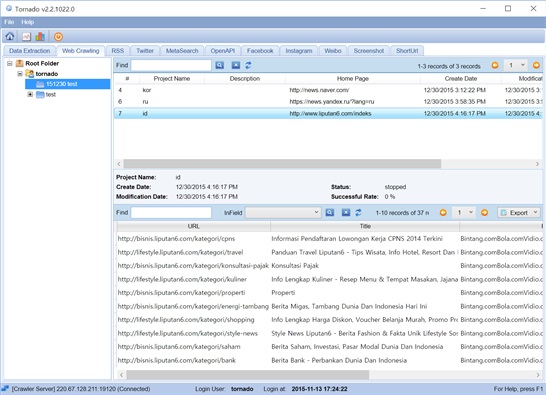
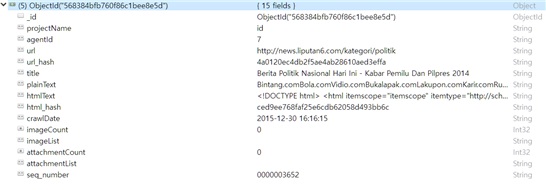
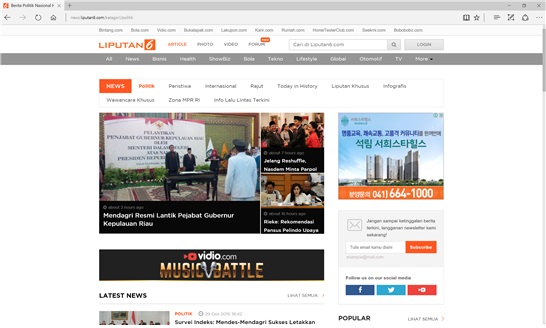
아래의 그림들은 실제 웹 수집이 이루어진 웹 사이트의 실제 모양과 웹 수집 결과가 저장된 MongoDB의 내용을 보여주고 있다. 실제 사이트에서는 사이트의 내용과 광고가 혼합되어 있음을 볼 수 있다. 그러나 저장된 DB에는 이미지가 생략되어 저장되며 텍스트만 저장된다.
로보몽고를 통한 크롤링 결과 확인
실제 웹 사이트
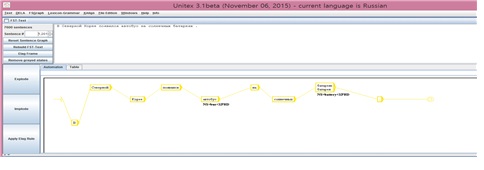
러시아어 사이트에 대한 동작 또한 인도네시아 경우와 유사하게 웹 수집이 이루어진다.
다음 그림은 러시아어 사이트에서 웹 수집을 위한 클라이언트 동작과 크롤링 결과를 보여준다.
토네이도에서 https://news.yandex.ru/?lang=ru 크롤링
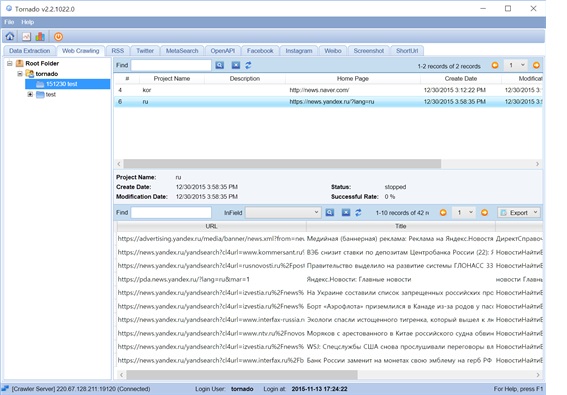
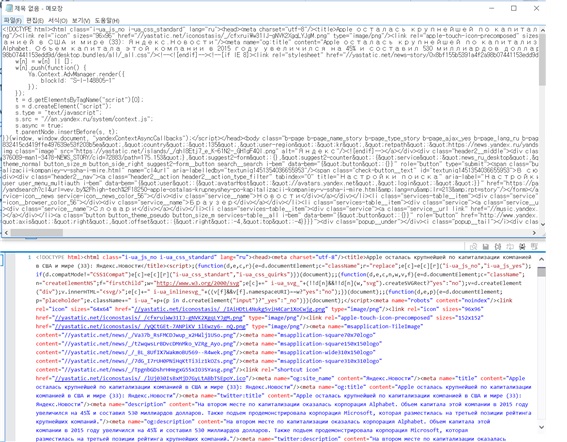
또한 실제 사이트와 실제 MongoDB에 저장된 내용, 그리고 웹 원본은 다음과 같다.
|
|
|
HTML 크롤링 결과 비교(상: 크롤링 / 하: 원본) |
다중 프로세서를 이용한 Flash 메모리 인터페이스 병렬화 처리 향상 기술 개발:
1차 년도에서는 글로벌 웹 데이터 수집 시스템을 벤치마킹으로 확장성 있는 데이터 저장/색인 시스템의 구조에 대한 연구를 위해, 데이터 저장장치에 대한 IO bandwidth에 대한 확장성을 보장해 주기 위한 저장장치 매체를 기반으로 한 연구를 수행 중이다. 구체적으로, 다음과 같은 저장 시스템의 하부 구조 및 입출력 연산에 대한 구조 및 방식에 대한 연구를 수행하였다.
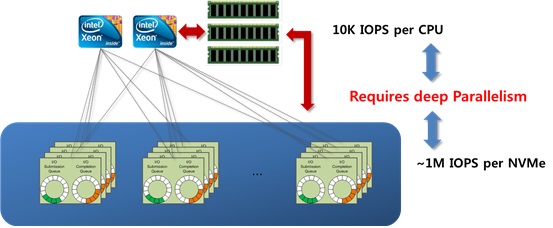
- 최근의 확장성 있는 저장 시스템은 저장 매체 중 낸드 플래시 기반 저장 매체를 기본으로 사용하고 있으며, 낸드 플래시 메모리 스토리지 시스템의 구조는 아래 그림과 같이, 플래시 컨트롤러(SSD Controller, eMMC controller 등)와 다수의 NAND 플래시 디바이스로 구성되어 있다.
- 플래시 컨트롤러와 낸드 플래시 메모리 어레이는 칩 안에 패키징되어 있을 수 있고 칩들이 외부 인터페이스에 의해서 서로 연결되어 있을 수도 있다. 또한, 최근의 플래시 컨트롤러는 고속의 성능을 위해서 Multi-Core를 사용하여 호스트 인터페이스 처리 및 플래시 인터페이스 처리를 병렬화 하고 있다.
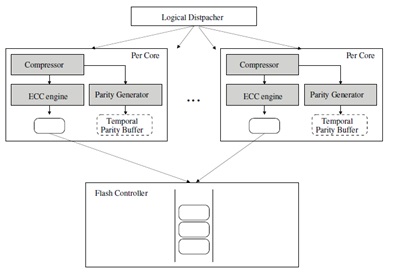
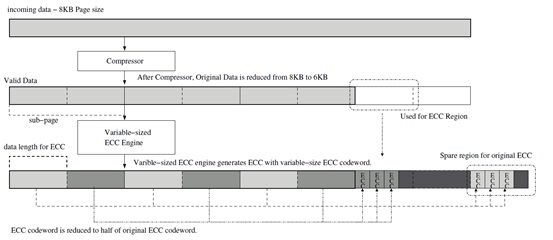
본 과제에서 진행하고 있는 연구 개발 내용은 Multi-Core 기반의 플래시 스토리지 시스템에서, 각 플래시 디바이스당 발생하는 쓰기 데이터에 대한 ECC encoding/decoding 방식에 대한 개선 방법으로써, 데이터에 대해서 Compression 및 Variable-Sized ECC coding 기법을 적용하여 ECC 데이터 생성 및 복원 하는 기법이다.
쓰기가 발생하면, Logical Dispatcher에 의해서 논리적인 주소에 대해서 병렬적으로 쓰기 연산을 분산시킨 뒤, 해당 Core로 할당한다. 해당 Core는 각 쓰기 연산에 대해서, Compression을 행한 후, Compressed Data에 대해서 Variable-Sized Encoding 기법을 적용하여 ECC data를 생성한다.
Compression 과 Variable-Sized Encoding 수행 방법을 아래 그림에서 조금 더 자세하게 도식화 하였다. 그림에서와 같이, Compression된 데이터에 의해서 줄어드는 영역을 자유 영역으로 사용할 수 있게 된다. 또한 Compressed 된 데이터는 크기가 작으므로, 기존 보다 더 작은 영역으로 분할하여 ECC codeword를 생성할 수 있게 되어, 줄어든 ECC codeword에 대해서 별도의 ECC를 더 생성하도록 한다.
그 결과, ECC가 필요한 데이터 영역이 확률적으로 줄어듦과 동시에, 보다 작은 영역에 대해서 ECC correction을 수행해 줄 수 있는 두 가지 이득을 볼 수 있다.
낸드 플래시 기반의 저장 시스템에서 가용성 및 확장성 있는 IO 연산을 개선하기 위한 방법으로 트림 코맨드를 개선하는 방식에 대한 연구를 수행하였다.
일반적으로 낸드 플래시 메모리 기반의 저장장치들은 낸드 플래시 메모리의 특성상 저장장치 내부의 관리를 위한 플래시 변환 계층(Flash Translation Layer, FTL)을 저장장치 내부에 두고, 호스트로부터의 논리주소에 대응해서 플래시 변환 계층에서 물리주소로 변환시켜서 관리해주고 있다.
이와 같은 특성으로 인해서 호스트 시스템의 논리 주소와 저장장치 내부의 물리주소간의 불일치가 발생하게 되고, 논리적으로 유효하다고 표시된 주소 영역에 대해서 실제 물리주소에는 유효하지 않은 데이터가 존재할 수 있으며 이를 제거해서 효율적인 IO를 보장해주는 코맨드가 TRIM 코맨드이다.
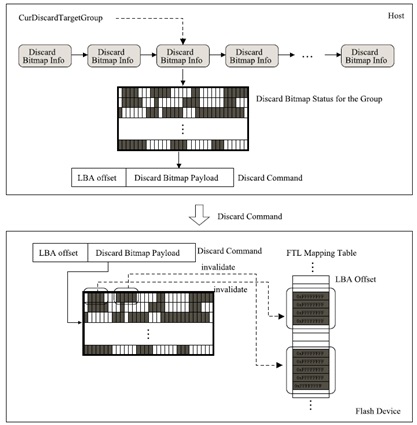
그런데, 기존의 TRIM Command의 형식은 (LBA, LBA+range)영역으로 무효화 영역을 구성한 리스트 형식으로 구성하였다. 이러한 TRIM command 형식은 작게 쪼개어진 많은 영역에 대해서는 효율적인 표시 형식이 될 수 없으며 너무 많은 TRIM 코맨드를 생성하여 저장 시스템의 IO bandwidth를 감소시킨다.
본 연구에서는 TRIM command의 표시 형식을 아래 그림과 같이 비트맵 단위의 표시 형식을 사용한 방식으로 구성하도록 설계 연구를 진행하였으며, 여기서, TRIM 비트맵은 비트맵 내의 하나의 비트가 무효화 주소 영역을 가리킨다. 호스트는 TRIM command를 생성할 때 payload 데이터에 비트맵의 일부를 첨부한다. 저장장치는 호스트로부터 받은 TRIM command의 payload 데이터인 비트맵을 분석하여, 무효화로 표시된 논리 주소 영역에 대해서 이에 대응되는 물리주소 영역을 무효화시킬 수 있다.
이렇게 비트맵 형식으로 구성된 TRIM command는 작게 쪼개어진 많은 주소 영역에 대해서 하나의 TRIM command로 구성할 수 있으므로, 호스트에서 저장장치로 전송하는 TRIM command의 횟수롤 감소시킬 수 있다.
이와 같은 연구를 진행하여 SCI급 국제저명학술지 1편과, 국내 특허 출원 1건의 결과를 내었다.
|
연구 주제 2 |
SG |
감성 사전 및 감성주석 코퍼스 설계 및 구축 |
평판 및 감성분석에 사용될 도메인별 코퍼스 구축을 위해 다음 과정을 거쳐 감성키워드, 문장 층위 및 토큰 층위의 감성주석코퍼스를 구축하기 위하여 한국어, 인도네시아어, 러시아어에 대해 다음과 같은 연구 내용을 추진하였다.
오피니언 분석을 위한 도메인 & 사이트 조사
기초 코퍼스 데이터 수집
수집된 코퍼스의 엑셀 데이터 환경 구축
긍정/부정 태깅된 문장 코퍼스 구축
유니텍스를 활용한 형태소 분석 및 개체명 감성단어 추출
코퍼스 기반 사전 구축
유니텍스 재적용 및 개체명 & 감성단어 태깅
개체명 & 감성단어 주석 코퍼스 구축
<코아 감성사전 및 감성주석코퍼스 연구 영역>
1. 오피니언 분석을 위한 도메인 연구 & 데이터 분류를 위한 태그셋 구축
태그셋 구축을 위한 분류 항목은 4 가지로 구분하였다. 즉 극성 분류, 이모티콘 극성 분류, 통사 정보, 철자법 정보로 나누었으며, 이때 극성 분류 기준은 긍정, 부정, 중립, 객관, 복합, 판단불가로 분류하고, 이모티콘 극성 분류는 긍정, 부정, 중립/복합으로, 통사 정보는 복문, 불완전문으로 나눔. 철자법 정보는 철자 오류/띄어쓰기 오류/링크 등으로 나누고, 통사 정보와 철자법 정보의 경우 해당 사항이 없으면 태깅하지 않는다.
객관 및 판단불가 태깅을 제외한 트위터 글을 유의미한 문장으로 분류한다
2. 수집된 데이터에 대하여 긍정/부정 감성 주석 부착된 코퍼스 구축
전체 112,238개의 트위터 문장을 수집하여 이를 일일이 연구자들이 태그셋에 따라 개별적으로 분류 및 분석하였다. 원시 트위터 문장에는 엄청난 양의 부적절 데이터(noise)가 많아서 최종적으로 29,508개의 문장만이 극성 분류 주석 코퍼스로서 유효한 것으로 판명되었다. 이들은 긍정/부정/중립/복합으로 태깅된 문장 코퍼스를 구성한다.
위와 같이 유효한 주석 코퍼스 문장들은 긍정(POSITIVE)으로 모두 13,187 단위, 부정(NEGATIVE)으로 모두 11,639 단위, 중립(NEUTRAL)으로 모두 2,928 단위, 그리고 복합(COMPLEX) 극성 표현으로 모두 2,530 단위가 나타났다.
3. 오피니언 문서의 감성 어휘 및 개체명 사전 구축 방법론 개발 및 데이터 구축
감성 분류는 전체 7 가지로 구분한다. 즉 강조 긍정(strongly positive), 긍정(positive), 중립(neutral), 부정(negative), 강조 부정(strongly negative), 상대(dependent), 강조 상대(accentuated dependency)로 분류하고 각각을 위한 태그셋 가이드라인을 완성한다.
개체명은 9 가지로 구분한다. PER(개인 인명 또는 개인과 관련된 일반명사), ORG(조직, 집단, 기업), GEO(지리적 공간), LOC(인공적 지명), DAT(명시적 날짜, 날짜로 표현하는 사건이나 이벤트), EVE(비명시적 날짜, 시간과 관련된 어휘), CON(이동 불가 물체, 부동산), PRD(이동 가능 구체 사물), CRE(추상적 대상)으로 분류한다.
중의적 대상은 개체명을 복수로 태깅한다. 예를 들어 ‘삼성: ORG, PRD’로 분류한다.
극성 분류된 문장 코퍼스에서 활용형을 추출하여 개체명 및 감성 분류 태깅 작업을 수행한다. 이를 통해 1,279개의 엔트리에 대한 태깅 작업을 완료하였다.
3. 감성 주석 코퍼스 반자동 구축을 위한 연구 방법론 개발 및 데이터 구축
초기 코퍼스로부터 추출하여 태깅 작업을 완료한 활용형을 유니텍스(Korean UNITEX) 플랫폼에서 코퍼스에 부트스트랩(Bootstrap) 방식으로 적용한다.
이를 통해 최종적으로 5,020개의 토큰 단위 감성 주석코퍼스를 구축하였다. 2차년도 연구에서 여기 나타난 중의성 경로 제거 문제 및 어절 단위 처리 문제, 오피니언 퀸터플(Quintuple)를 구현하는 연구를 본격화하기 위한 토대연구의 기능을 수행하였다.
<다국어 감성사전 및 감성주석 코퍼스 연구 영역>
1. 인도네시아어/러시아어 도메인 연구 & 데이터 분류를 위한 태그셋 구축
앞서 코아 연구 토대에 기초하여 이와 호환 가능하도록 동일한 원칙으로 수행되었다.
즉 태그셋 구축을 위한 분류 항목은 4 가지로 구분하였다. 즉 극성 분류, 이모티콘 극성 분류, 통사 정보, 철자법 정보로 나누었으며, 이때 극성 분류 기준은 긍정, 부정, 중립, 객관, 복합, 판단불가로 분류하고, 이모티콘 극성 분류는 긍정, 부정, 중립/복합으로, 통사 정보는 복문, 불완전문으로 나눔. 철자법 정보는 철자 오류/띄어쓰기 오류/링크 등으로 나누고, 통사 정보와 철자법 정보의 경우 해당 사항이 없으면 태깅하지 않는다. 객관 및 판단불가 태깅을 제외한 트위터 글을 유의미한 문장으로 분류한다
2. 인도네시아어/러시아어 원시 데이터에 대하여 긍정/부정 감성 주석 부착된 코퍼스 구축
인도네시아어의 경우, 전체 288,015개의 트위터 문장을 수집하여 이를 일일이 연구자들이 태그셋에 따라 개별적으로 분류 및 분석하였고, 이 경우 코아(한국어) 코퍼스보다 훨씬 더 부적절 데이터(noise)가 많아서 최종적으로 20,466개의 문장만이 극성 분류 주석 코퍼스로서 유효한 것으로 판명되었다. 이들은 긍정/부정/중립/복합으로 태깅된 문장 코퍼스를 구성한다.
이와 같이 유효한 주석 코퍼스 단위 19,466개의 문장에 대한 긍정/부정/중립/복합 태깅된 문장 코퍼스를 구축하였으며, 여기서 광고 및 객관적인 내용을 담고 있는 것으로 판명된 코퍼스는 전체 104,299개에 이르는 것을 확인할 수 있었다.
이들에 대한 통계적 지표는 추후 2차년도에서 본격적인 연구 방법론 개발 및 데이터 확장시에 매우 중요한 자료가 될 것으로 판단된다.
러시아어의 경우, 1차년도에는 인도네시아어와 달리 <토대연구>의 성격을 보이므로 규모에 있어서는 축소된 성격을 가지나, 전체 진행 방식은 동일하다. 전체 7,735개의 트위터 문장에 대한 개별적 분석과 점검을 일일이 진행하였으며, 그 결과 3,100개의 문장이 감성 주석 코퍼스로서 유의미한 것으로 판명되었다. 따라서 이들 3,100여개에 대해 긍정/부정/중립/복합 태깅된 문장 코퍼스를 구축하였다.
3. 인도네시아어/러시아어 형태론적 특징 및 언어속성별 태그셋 구축을 위한 토대 연구
인도네시아어의 경우 8품사 기반으로 인도네시아어 문장을 분석하고 주석 작업함. 동시에 외래어와 잘못된 표기도 일련의 별도 정보와 함께 표시하여 사전 표제어로 등재하며, 기본 품사 정보 외에 극성에 대한 강도 정보 표기한다.
인도네시아어 개체명 태그셋 및 감성 분류 체계를 연구하여, 연계성을 고려하여 한국어와 분류 체계를 통일하였고, 품사 정보에는 명사, 형용사, 부사, 동사를 표기하고 7가지로 감성 분류를 구분함.
러시아어의 경우는 품사는 러시아어 품사 분류 체계를 따라 10 품사로 분류함하였다. 즉 명사, 동사, 형용사, 부사, 대명사, 수사, 전치사, 접속사, 소사, 감탄사로 나누었고, 형태 변화 품사의 Lemma는 일반 해석 사전 표제어 형태를 기준으로 설정하였다. 즉 명사 - 단수 주격 형태, 대명사 - 남성 단수 주격 형태, 동사 - 불완료상 infinitive 형태, 형용사 - 장어미 남성 단수 주격 형태, 수사 – 개수사 : 주격 형태, 서수사 – 남성 단수 주격 형태로 설정하였다. 부사, 전치사, 접속사, 소사, 감탄사의 다섯 품사는 형태 변화하지 않는다.
러시아어 개체명 태그셋 및 감성 분류 체계 연구도, 연구 연계성을 고려하여 한국어 및 인도네시아어와 분류 체계와 호환되는 방식으로 진행하였다.
4. 인도네시아어/러시아어 감성 어휘 및 개체명 사전 구축 방법론 개발 및 데이터 구축
인도네시아어/러시아어의 경우도 앞서 코아 사전의 경우에서처럼 전체 감성 분류는 전체 7 가지로 구분한다. 즉 강조 긍정(strongly positive), 긍정(positive), 중립(neutral), 부정(negative), 강조 부정(strongly negative), 상대(dependent), 강조 상대(accentuated dependency)로 분류하고 각각을 위한 태그셋 가이드라인을 완성하였다.
개체명은 9 가지로 구분한다. PER(개인 인명 또는 개인과 관련된 일반명사), ORG(조직, 집단, 기업), GEO(지리적 공간), LOC(인공적 지명), DAT(명시적 날짜, 날짜로 표현하는 사건이나 이벤트), EVE(비명시적 날짜, 시간과 관련된 어휘), CON(이동 불가 물체, 부동산), PRD(이동 가능 구체 사물), CRE(추상적 대상)으로 분류하고, 중의적 대상은 개체명을 복수로 태깅한다. 예를 들어 ‘삼성: ORG, PRD’로 분류한다.
인도네시아어의 경우는 기초 극성 분류된 유의미한 문장 코퍼스로부터 언어학 전공자가 14,997개의 활용형 엔트리를 확인하고 분석하여 9,977개의 활용형을 추출하였고, 최종적으로 이중에서 3,331개의 lemma를 획득하였다. 그 가운데 1,400개의 활용형에 대해 태그셋을 부여하였다.
궁극적으로 이를 유니텍스 환경에서 부트스트랩 방식으로 적용하여 반자동 주석 코퍼스를 구축하기 위한 연구 방법론을 개발하였다.
러시아어의 경우는 구축된 문장 코퍼스를 기반으로 토큰 분리 작업 수행한 후, 분리된 토큰에 대한 개체명 및 극성 부여 작업 등을 진행하여 전체 801개를 추출하였고, 최종적으로 이중에서 유의미한 토큰이 656개, Lemma가 334개로 나타났다. 획득된 활용형 가운데 130개에 대해 태그셋을 부여가 완료되었다. 이 경우도 궁극적으로 이를 유니텍스 환경에서 부트스트랩 방식으로 적용하여 반자동 주석 코퍼스를 구축하기 위한 연구 방법론을 개발하였다.
5. 인도네시아어/러시아어 감성 주석 코퍼스 반자동 구축을 위한 연구 방법론 개발 및 데이터 구축
코아 코퍼스의 모델링에 입각하여 인도네시아어/러시아어의 경우도 동일한 방식으로 개발되었다. 즉 1차 주석 부착 코퍼스로부터 추출하여 태깅 작업을 완료한 활용형을 유니텍스(Korean UNITEX) 플랫폼에서 코퍼스에 적용하는 부트스트랩(Bootstrap) 연구 방법론을 개발하였다.
인도네시아어의 경우, 최종적으로 6,122개의 토큰 단위 감성 주석코퍼스를 구축하였다. 2차년도 연구에서 여기 나타난 중의성 경로 제거 문제 및 어절 단위 처리 문제, 오피니언 퀸터플(Quintuple)를 구현하는 연구를 본격화하기 위한 토대연구의 기능을 수행하였다.
러시아어의 경우도 최종적으로 626개의 토큰 단위 감성 주석코퍼스를 구축하였고, 2차년도 연구에서, 여기 나타난 중의성 경로 제거 문제 및 어절 단위 처리 문제, 오피니언 퀸터플(Quintuple)를 구현하는 연구를 본격화하기 위한 토대연구의 기능을 수행하였다.
APPENDIX
인도네시아어의 경우, 문장 단위 감성 주석 코퍼스에 태그셋 정보가 부착된 예
인도네시아어의 경우, 감성 키워드 활용사전 구축을 위한 테이블 형식의 자료구조 예
인도네시아어의 경우, 토큰 단위 감성 주석 코퍼스를 반자동으로 구축하는 프로세싱의 예
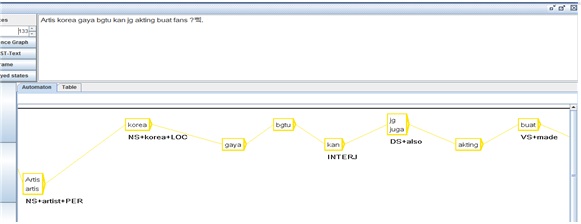
예문 1) Gaya Korea Jadi Imej Baru. ‘한국스타일 너무 새로운 느낌이에요.’
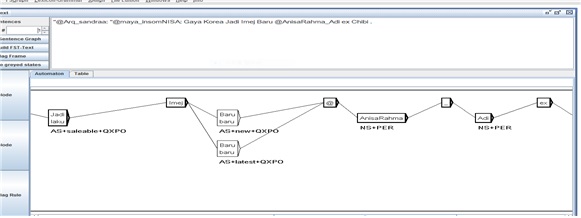
예문 2) Artis korea gaya bgtu kan jg akting buat fans?
‘한국 배우들의 행동하는 방식이 팬들에게는 괜찮은가요?’
러시아어의 경우, 문장 단위 감성 주석 코퍼스에 태그셋 정보가 부착된 예
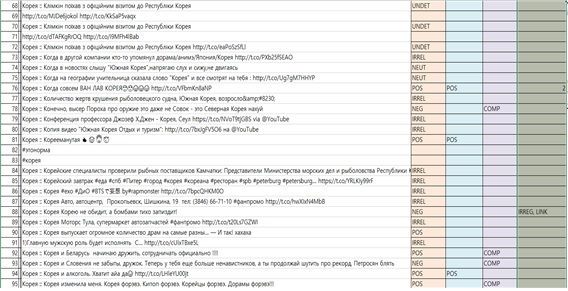
러시아어의 경우, 감성 키워드 활용사전 구축을 위한 테이블 형식의 자료구조 예
러시아어의 경우, 토큰 단위 감성 주석 코퍼스를 반자동으로 구축하는 프로세싱의 예
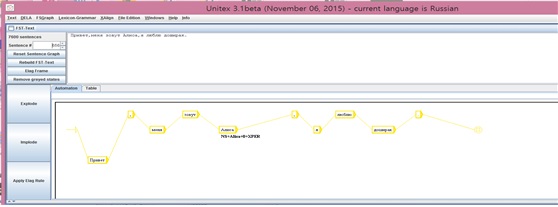
예문 1) В Северной Корее появился автобус на солнечных батареях.
‘ 북한에 태양 전지로 움직이는 버스가 등장했다.’
예문 2) Привет, меня зовут Алиса, я люблю доширак.
‘안녕, 내 이름은 알리사야, 난 도시락을 좋아해.’
연구 주제 3 KL Shallow 기계 학습 기반 다국어 평판/감성 분석 테스트베드 구축
1. 전체 구성
기계 학습 기반의 다국어 평판/감성 분석 테스트베드 구축을 위하여 단일언어 환경에서 동작하는 Shallow 기계학습 평판분석 엔진을 구축하였다. 다음 그림은 구축된 감성분석기 구성을 보여준다.
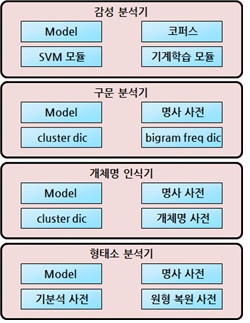
가장 하단의 형태소 분석기는 상단의 모든 분석의 기본이 된다. 개체명 분석의 경우 특성을 추출하기 위하여 형태소 분석 결과를 사용하게 되며, 구문분석과 감성분석 또한 형태소 분석 결과를 사용하게 된다. 모든 분석 기능은 기계학습 방법을 사용하며, 특히 Structural SVM(Support Vector Machine) 방식을 사용하고 있다. 각 분석은 하단의 분석을 필요로 하기 때문에, 상단으로 갈수록 분석 속도가 느려지게 되며 품질 또한 떨어지게 된다.
서포트 벡터 머신(support vector machine, SVM)은 기계 학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와 회귀 분석을 위해 사용한다. 두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, SVM 알고리즘은 주어진 데이터 집합을 바탕으로 하여 새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만든다. 만들어진 분류 모델은 데이터가 사상된 공간에서 경계로 표현되는데 SVM 알고리즘은 그 중 가장 큰 폭을 가진 경계를 찾는 알고리즘이다. SVM은 선형 분류와 더불어 비선형 분류에서도 사용될 수 있다. 비선형 분류를 하기 위해서 주어진 데이터를 고차원 특징 공간으로 사상하는 작업이 필요한데, 이를 효율적으로 하기 위해 커널 트릭을 사용한다. Structural SVM은기존의SVM을 확장한 기계 학습 알고리즘으로, 기존의 SVM이 바이너리 분류, 멀티클래스 분류 등을 지원하는 반면, SSVM은 더욱 일반적인 구조의 문제(예를들어, sequence labeling, 구문 분석 등)를 지원한다.
2. 형태소 분석
형태소 분석이란 어떤 대상 어절의 모든 가능한 분석 결과를 출력하는 것을 의미한다. 형태소 분석 단계에서 문제가 되는 부분은 미등록어, 오탈자, 띄어쓰기 오류 등을 들 수 있는데, 이들은 형태소 분석에치명적인 원인이라 할 수 있다. 또 다른 문제로는 복합명사 분해가 있을 수 있다. '복합명사'는 '복합 + 명사', '복 + 합명사', '복합명 + 사' 등의 다양한 방식으로 쪼개질 수 있는데 이들 중에서 가장 적합한 분해 결과를 선택하는 문제이다. 형태소 분석 학습 및 분석 절차는 다음과 같다.
형태소 분석기의 특징은 다음과 같다.
음절 기반 형태소 분석 및 품사 태깅 방법을 사용하여 명사 추출에 용이하다.
44개의 형태소를 지원한다.
자바로 개발되어 OS에 독립적으로 실행된다.
형용사, 동사 등의 용언에 대한 원형을 복원하는 기능을 제공한다.
F1 기준 98% 이상의 높은 성능을 제공한다.
멀티스레드를 지원한다.
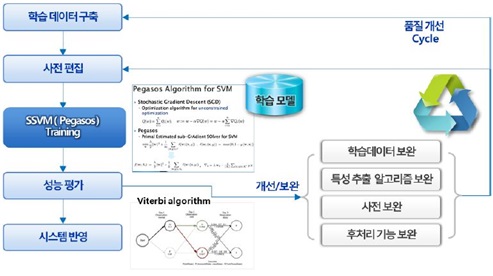
기계학습에 Structual-SVM 알고리즘과 Pegasos 알고리즘을 적용하였다.
3. 개체명 인식
개체명이란 사람이름, 회사이름, 지명, 영화제목, 날짜, 시간 등을 말하며, 텍스트에서 이런 개체명을 찾아서 해당하는 의미의 범주를 결정하는 것을 개체명 인식이라 한다. 개체명은 품사로는 고유명사 또는 미등록어인 경우가 많으며, 향상 새롭게 만들어지고, 때로는 같은 단어라도 사용되는 문장에 따라 상이한 의미를 나타낸다. 또 개체명은 고유명사나 미등록어 하나가 하나의 개체명을 이룰 수도 있지만, 대부분의 개체명은 2개 이상의 고유명사나 일반명사와 결합하여, 복합명사 혹은 명사구 형태를 보이기 때문에, 그 경계를 인식하기는 쉽지 않다. 분석이란 어떤 대상 어절의 모든 가능한 분석 결과를 출력하는 것을 의미한다. 구축에 사용된 개체명 인식기는 기계학습 방법을 사용하여 텍스트로부터 개체명을 인식하여 해당 개체명 태그를 달아 주는 시스템으로 기존 HMM에 비해 높은 성능을 보이는 기계학습모델(ssvm)을 적용하여 다양한 Feature 이용이 가능하며, 새로운 도메인 분야에 대한 적용이 용이하며, 기존 정의된 개념 외에 신규 개념을 추출하는데 용이하다. 다음 그림은 개체명 인식기의 학습 및 분석 절차를 도시하고 있다.
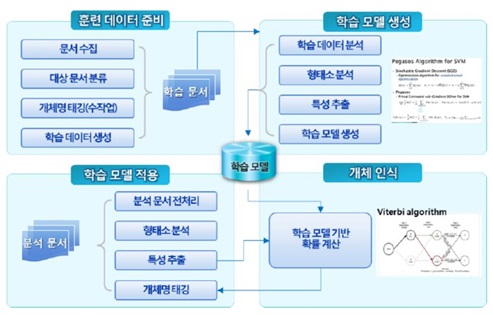
4. 구문 분석
구문 분석(구문해석, 문장해석)은 문장을 그것을 이루고 있는 구성 성분으로 분해하고 그들 사이의 위계 관계를 분석하여 문장의 구조를 결정하는 것을 말한다. 구문 분석은 다음과 같은 절차와 특징을 가지고 있다.
한글로 된 단어들의 선형적 나열인 문장으로부터 그 문장에 내포되어 있는 문법적 구조를 찾아낸다.
이러한 문법적 구조를 바탕으로 정확한 뜻을 컴퓨터가 이해할 수 있도록 한다.
구문 분석의 결과는 개체명인식, 의미역 결정 및 감성 분석 등 다양한 자연 언어 처리 응용 시스템에서 사용된다.
이벤트 추출 및 감성 분석에 있어 구문 분석은 필수 기능이라고 할 수 있다.
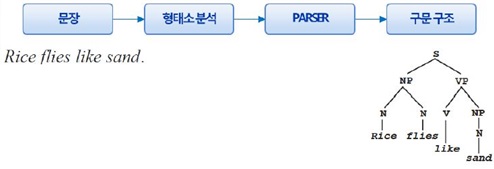
구문 분석 결과의 그래픽 표현의 예는 아래와 같다.

구문 분석의 전형적인 흐름은 아래의 그림과 같다.
5. 감성 분석
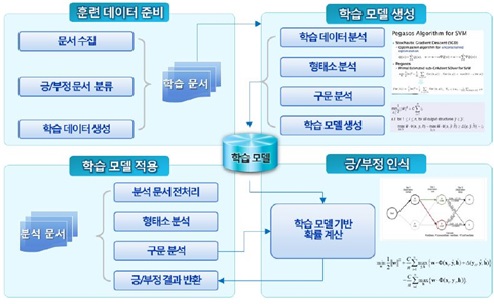
어떤 주제에 대한 긍정적이거나 부정적인 의견 표출에 대한 요약된 정보를 제시해 주거나 어떤 주제에 대한 보다 상세한 항목에 대한 가를 요약해서 제시해 주는 것으로, 이러한 분석의 응용은 '감성분석(sentiment analysis)', '의견분석(opinion mining)', '감성분석(emotion analysis)' 등으로 불린다. 감성분석은 통산 3단계로 이뤄진다. 첫 번째는 각종 소셜 미디어 매체에서 정보를 수집하는 '데이터수집' 단계다. 두 번째는 이렇게 총체적으로 수집된 정보에서 사용자의 주관이 드러난 부분만을 걸러내는 '주관성탐지' 과정이다. 마지막 세 번째 단계에서는 '극성탐지' 작업이 이뤄지는데, 이는 추출된 감성 데이터를 '좋음'과 '싫음'의 양 극단으로 분류하는 과정이다.
감성 분석기의 학습 및 분석 절차는 다음과 같다.
6. 구축 시스템 라이브러리
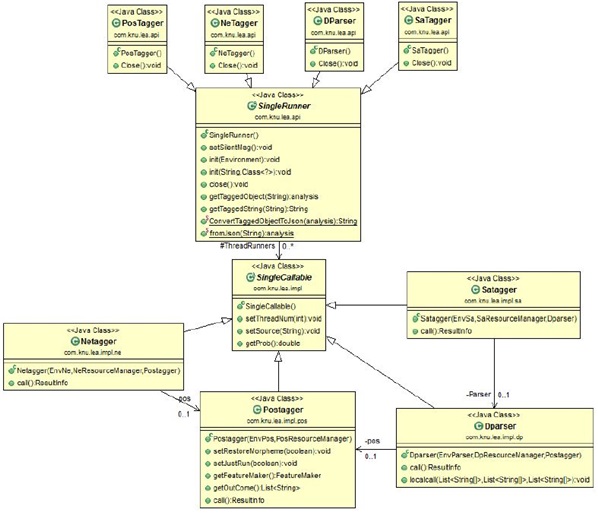
구축된 시스템의 각 분석기에 대한 API 클래스 흐름도는 다음과 같다.
PosTagger, NeTagger, DParser, SaTagger는 각각 외부에서 호출 가능한 외부인터페이스 영역으로, SingleRunner를 상속받아 구현되어 있으며, 각 분석에 필요한 사전 및 모델을 정의하도록 하며initialization(), 각 결과는 아래의 두 개의 함수를 사용하여 반환 받을 수 있다.
public Analysis getTaggedObject(String Source)
public String getTaggedString(String Source)
결과 정보 객체 - getTaggedObject(String Source)의 결과
분석 결과는 어떤 분석을 수행하던지 Analysis 객체에 담겨 반환하게 된다. Analysis에는 분석을 의뢰한 원본 정보를 포함하고 있으며, 문장으로 분리될 경우를 위해서 Sentence 객체를 0개 이상 포함할 수 있다. 각 문장 단위로 형태소 분석 결과를 표현하는 Morph, Word 객체를 포함하고 있으며, 구문 분석결과를 포함하고 있는 Dependency 객체, 개체명 인식 결과를 포함하고 있는 NamedEntity 객체, 감성 분석 결과를 포함하고 있는 Sentiment 객체를 0개 이상 포함할 수 있다.
결과 정보 스트링(json) - getTaggedString(String Source)
Json 결과를 사용할 경우 아래와 같은 형태의 Json이 생성되며, 이는 정확히 Aanalysis 객체와 매핑된다. 아래의 코드를 사용하여 Json <-> Analysis 로 변환할 수 있다.
JsonUtil.TaggedObjectToJson(Analysis obj)
JsonUtil.JsonToTaggedObject(String json) throws JsonSyntaxException
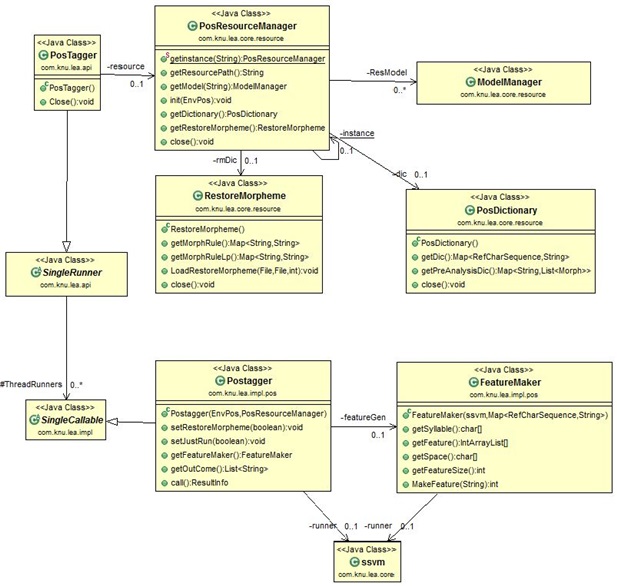
형태소 분석 클래스 구조
형태소 분석기는 사전(PosDictionary)과 원형복원(RestoreMorpheme)을 위한 사전을 사용하여 초기화하고, 문장으로 분리 가능할 경우 내부 스레드를 사용하여 동시에 분석을 수행하게 된다. 내부 Postagger는 입력된 문장을 분석하여 Feature를 생성하고, ssvm 모델을 사용하여 분석을 수행하게 된다.
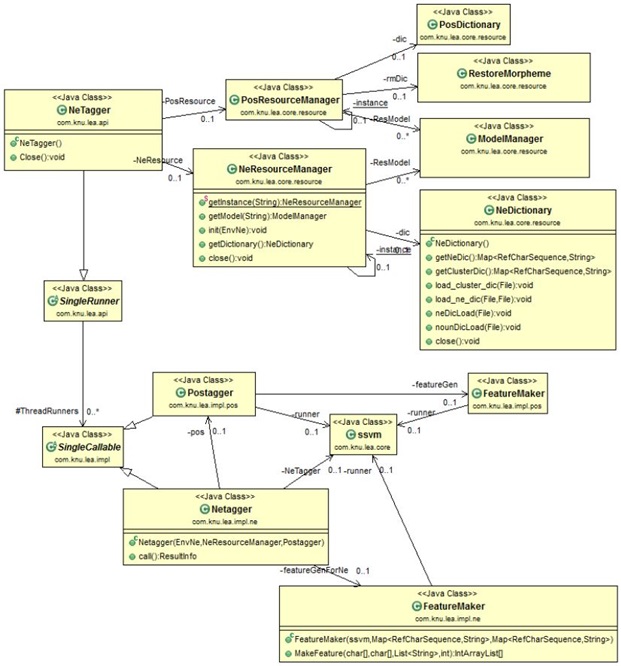
개체명 분석 클래스 구조
개체명 분석을 수행하기 위해서는 Postagger를 내부적으로 사용하게 되며, 초기화시 형태소 분석을 위한 자원과, 개체명 분석을 수행하기 위한 사전을 사용하여 초기화된다. 내부에서 Nettager는 형태소 분석 결과를 사용하여 특성을 추출한 후 ssvm을 사용하여 분석을 수행하게 된다.
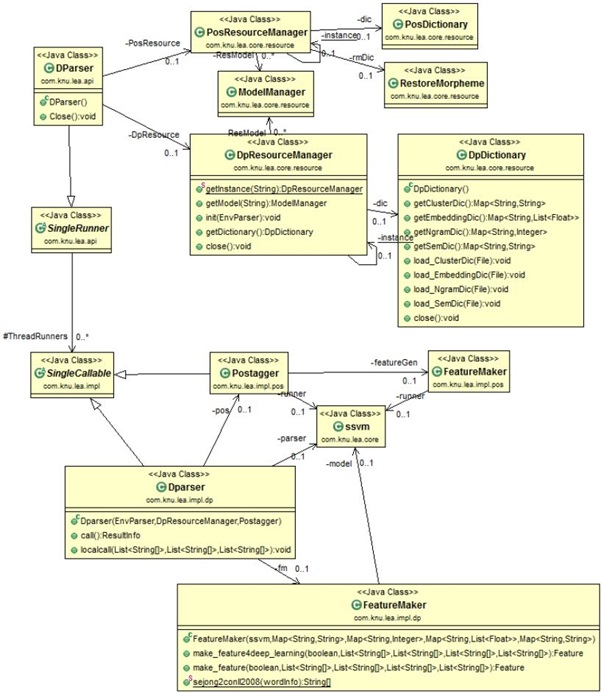
구문 분석 클래스 구조
구문 분석을 수행하기 위해서는 Postagger를 내부적으로 사용하게 되며, 초기화시 형태소 분석을위한 자원과, 구문 분석을 수행하기 위한 사전을 사용하여 초기화된다. 내부에서 Dparser는 형태소 분석 결과를 사용하여 특성을 추출한 후 ssvm을 사용하여 분석을 수행하게 된다.
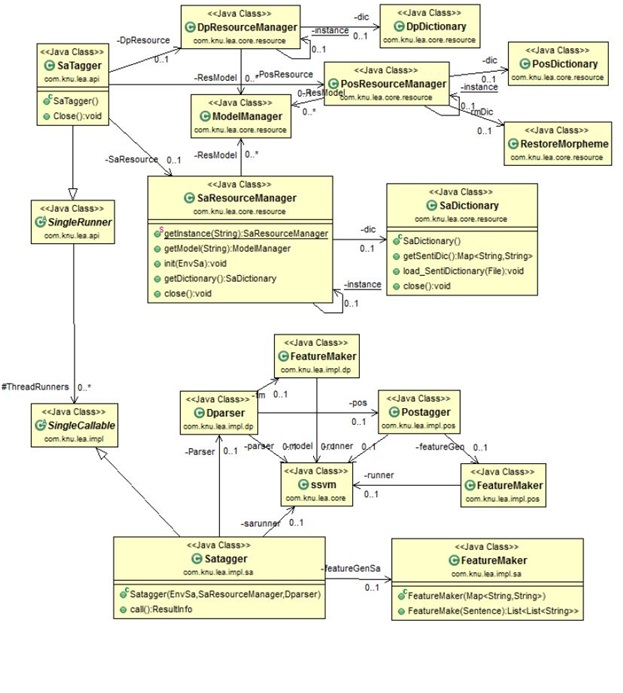
감성 분석 클래스 구조
감성 분석을 수행하기 위해서는 Dparaser를 내부적으로 사용하게 되며, 초기화시 구문분석을 위한 자원과, 형태소 분석을 수행하기 위한 사전을 사용하여 초기화된다. 내부에서 감성 분석은 형태소 분석 결과와 구문 분석 결과를 사용하여 특성을 추출한 후 ssvm을 사용하여 분석을 수행하게 된다.
감성 분석 플랫폼은 웹 수집기와 동일한 사양의 서버 1대에 구축되었으며 웹 API를 사용하여 문장에 대한 감성 분석 결과를 제공하고 있다.
|
연구 주제 4 |
WP3-KL |
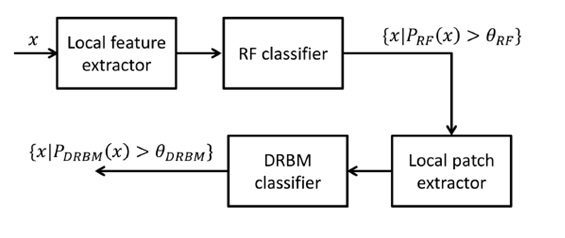
의료 영상 분석을 위한 고차원 특징 추출 기술 개발 |
특징기반으로 의료 영상에서 유방암 여부를 파별하는 연구를 진행하였다. 아래 그림에서와 같은 방법은 각 지역적으로 특징을 추출하여 Random forest 분류기로 관심 영역들을 추출하고 이를 기반으로 초기 딥 러닝 기법에 하나인 Deep Restricted Boltsman Machine 기법에 적용하여 state of the art에 해당하는 성과를 보였다.
영상 분석을 위한 유방 초음파 기초 DB 수집
축적된 데이터베이스를 기반으로 전문가의 판독 BIRADS 데이터베이스 구축
이 두 특성과 생검으로 알게 된 결과를 학습 시키고 분류기를 설계함